
大家好!今天,我非常兴奋地向你们展示如何构建一个Python应用程序,它采用网页内容并生成基于最新谷歌指南的优化报告——所有这些都在不到10秒的时间内完成!这对于希望确保他们的内容符合谷歌标准的博客作者和内容创作者来说是完美的。
我们将使用Llama索引ReActAgent以及三个工具,使人工智能代理能够:
- 从给定的URL读取博客文章的内容。
- 处理谷歌的内容指南。
- 根据内容和指南生成PDF报告。
鉴于最近谷歌更新影响了众多博客主的自然流量,这一点尤其有用。你可能需要根据需要调整这个,但总的来说,如果你想探索AI代理,这应该是一个很好的起点。
好的,让我们开始构建这个!
概述和范围
以下是我们将要介绍的内容:
- 架构概述
- 设置环境
- 创建工具
- 编写主要应用程序
- 运行应用程序
一.架构概述
“ReAct”指的是“推理和行动”。ReAct代理理解并生成语言,进行推理,并根据这种理解执行行动,由于LlamaIndex提供了一个创建ReAct代理和工具的便捷且易于使用的界面,我们将使用它和OpenAI的最新模型GPT-4o来构建我们的应用程序。
我们将创建三个简单的工具:
- 这个
guidelines工具:将谷歌的指南转换为嵌入物以供参考。 - 这个
web_reader工具:读取指定网页的内容。 - 这个
report_generator工具:将模型的响应从Markdown转换为PDF报告。
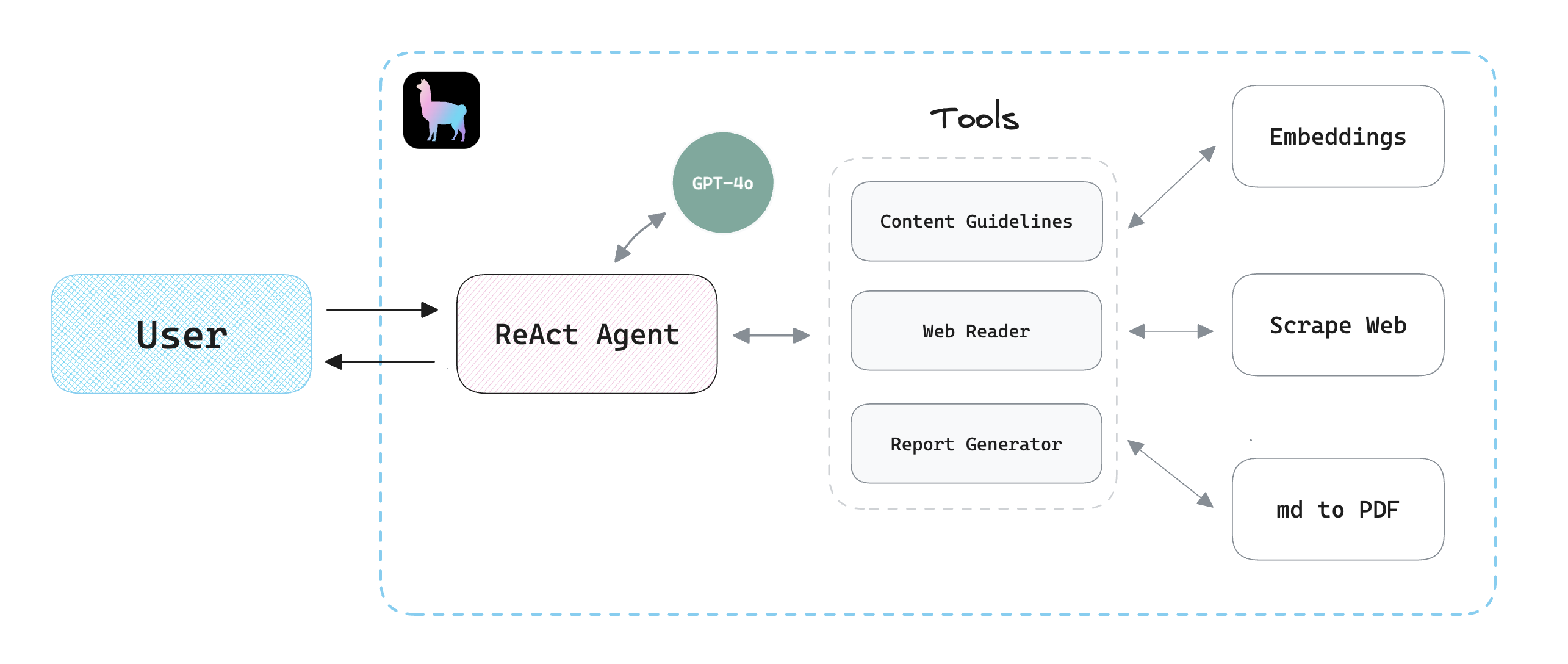
LlamaIndex ReAct代理架构
2.设置环境
让我们从创建一个新的项目目录开始。在其中,我们将设置一个新的环境:
mkdir llamaindex-react-agent-demo
cd llamaindex-react-agent-demo
python3 -m venv venv
source venv/bin/activate
接下来,安装必要的软件包:
pip install llama-index llama-index-llms-openai
pip install llama-index-readers-web llama-index-readers-file
pip install python-dotenv pypandoc
💡 要将内容转换为PDF我们将使用一个名为第三方工具pandoc. 你可以跟随按照这里概述的步骤在您的计算机上设置它。
最后,我们将创建一个.env在根目录中创建一个文件,并按照以下方式添加我们的OpenAI API密钥:
OPENAI_API_KEY="PASTE_KEY_HERE"
您可以从这里获取您的OpenAI API密钥这个网址。
谷歌嵌入式内容指南
浏览任何页面。在这个教程中,我使用本页. 一旦你到达那里,将其转换为PDF格式。通常情况下,你可以通过点击“文件 -> 导出为PDF…“或者根据你的浏览器不同,显示的内容也有所不同。
将谷歌的内容指南保存为PDF格式,并将其放置在data文件夹。然后,创建一个tools文件夹并添加guidelines.py文件:
import os
from llama_index.core import StorageContext, VectorStoreIndex, load_index_from_storage
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.readers.file import PDFReader
...
在添加了所需的包之后,我们将把我们的PDF转换成嵌入,然后创建一个VectorStoreIndex:
...
data = PDFReader().load_data(file=file_path)
index = VectorStoreIndex.from_documents(data, show_progress=False)
...
然后,我们返回QueryEngineTool这可以被代理使用:
...
query_engine = index.as_query_engine()
guidelines_engine = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="guidelines_engine",
description="This tool can retrieve content from the guidelines"
)
)
网页阅读器
接下来,我们将编写一些代码,使代理能够读取网页的内容。创建一个web_reader.py在文件tools文件夹:
# web_reader.py
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.readers.web import SimpleWebPageReader
...
url = "https://www.gettingstarted.ai/crewai-beginner-tutorial"
documents = SimpleWebPageReader(html_to_text=True).load_data([url])
index = SummaryIndex.from_documents(documents)
我正在使用SummaryIndex要处理这些文件,您可以根据您的数据选择多种其他索引类型。
我还在用SimpleWebPageReader拉取URL的内容。或者,您可以实现自己的函数,但我们将只使用这个数据加载器以保持事情简单。
接下来,我们将构建QueryEngineTool对象将像以前一样提供给代理:
query_engine = index.as_query_engine()
web_reader_engine = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="web_reader_engine",
description="This tool can retrieve content from a web page"
)
)
好的,酷。现在让我们将工具打包,并创建我们的PDF报告生成器。
PDF报告生成器
对于这个,我们将使用FunctionTool而不是QueryEngineTool因为代理不会查询索引,而是执行一个Python函数来生成报告。
首先创建一个report_generator.py在文件tools文件夹:
# report_generator.py
...
import tempfile
import pypandoc
from llama_index.core.tools import FunctionTool
def generate_report(md_text, output_file):
with tempfile.NamedTemporaryFile(delete=False, suffix=".md") as temp_md:
temp_md.write(md_text.encode("utf-8"))
temp_md_path = temp_md.name
try:
output = pypandoc.convert_file(temp_md_path, "pdf", outputfile=output_file)
return "Success"
finally:
os.remove(temp_md_path)
report_generator = FunctionTool.from_defaults(
fn=generate_report,
name="report_generator",
description="This tool can generate a PDF report from markdown text"
)
我正在使用pypandoc这是一个Pandoc包装器,所以如果你使用上面的代码,请确保它已经安装在你的系统上。有关安装说明,按照这个指南.
4.编写主应用程序
太棒了!一切都很好。现在我们将把所有的东西放在一起main.py文件:
# main.py
...
# llama_index
from llama_index.llms.openai import OpenAI
from llama_index.core.agent import ReActAgent
# tools
from tools.guidelines import guidelines_engine
from tools.web_reader import web_reader_engine
from tools.report_generator import report_generator
llm = OpenAI(model="gpt-4o")
agent = ReActAgent.from_tools(
tools=[
guidelines_engine, # <---
web_reader_engine, # <---
report_generator # <---
],
llm=llm,
verbose=True
)
...
正如你看到的,我们首先导入所需的包和工具,然后我们将使用ReActAgent创建我们的类agent.
要创建一个简单的聊天循环,我们将编写以下代码,然后运行应用程序:
...
while True:
user_input = input("You: ")
if user_input.lower() == "quit":
break
response = agent.chat(user_input)
print("Agent: ", response)
五.运行应用程序
表演时间到了!让我们从终端运行应用程序:
python main.py
请随意使用以下提示,或者根据您的需要进行定制:
“根据给定的网页,开发可操作的提示,包括如何重写一些内容,以优化它,使其更符合内容指南。你必须在表格中解释为什么每项建议根据指南改进内容,然后创建一个报告。”
代理将处理请求,并按需调用工具,以生成包含可操作提示和解释的PDF报告。
整个过程看起来会像这样:

演示:在终端中运行代理
你可以清楚地看到代理是如何推理和思考手头的任务,然后制定执行计划的。有了我们创建的工具的帮助,我们可以给它额外的能力,比如生成PDF报告。
这是最终的PDF报告:

生成PDF报告
结论
就这样!你已经构建了一个智能AI代理,它可以基于谷歌的指南优化你的博客内容。这个工具可以节省你大量的时间,并确保你的内容始终达到标准。
确保创建一个免费帐户以获取下面的完整源代码。另外,让我们在X上连接并订阅我的YouTube频道更多!我很乐意知道您是否有任何问题或反馈。
很快见到你!
更多关于人工智能入门
更多来自网络
原文链接:Tutorial: Build Your Own RAG AI Agent with LlamaIndex
本文使用 🐝 A C(Collect) -> T(Transform) -> P(Publish) automation workflow for content creator. 全自动采集 - 翻译 - 发布

留下评论